
Cloud Computing:
Benefits of cloud computing:
1. CostTypes of cloud computing
Not all clouds are the same and not one type of cloud computing is right for everyone. Several different models, types and services have evolved to help offer the right solution for your needs.
First, you need to determine the type of cloud deployment or cloud computing architecture, that your cloud services will be implemented on. There are three different ways to deploy cloud services: on a public cloud, private cloud or hybrid cloud.
Public clouds are owned and operated by a third-party cloud service providers, which deliver their computing resources like servers and storage over the Internet. Microsoft Azure is an example of a public cloud. With a public cloud, all hardware, software and other supporting infrastructure is owned and managed by the cloud provider. You access these services and manage your account using a web browser.
Private cloud
Hybrid cloud
Hybrid clouds combine public and private clouds, bound together by technology that allows data and applications to be shared between them. By allowing data and applications to move between private and public clouds, a hybrid cloud gives your business greater flexibility, more deployment options and helps optimize your existing infrastructure, security and complianceTypes of cloud services:
Today, everyone are moving towards Cloud World (AWS/GCP/Azure/PCF/VMC). It might be a public cloud, a private cloud or a hybrid cloud.
But are you aware of what are Services Cloud Computing provides to us ????
Majorly there are three categories of Cloud Computing Services:
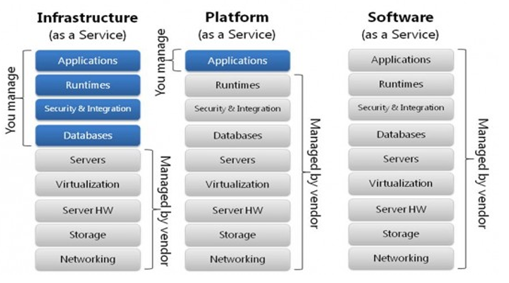
a) Infrastructure as a Service (IaaS) : It provides only a base infrastructure (Virtual machine, Software Define Network, Storage attached). End user have to configure and manage platform and environment, deploy applications on it.
AWS (EC2), GCP (CE), Microsoft Azure (VM) are examples of Iaas.
b) Software as a Service (SaaS) : It is sometimes called to as “on-demand software”. Typically accessed by users using a thin client via a web browser. In SaaS everything can be managed by vendors: applications, runtime, data, middleware, OSes, virtualization, servers, storage and networking, End users have to use it.
GMAIL is Best example of SaaS. Google team managing everything just we have to use the application through any of client or in browsers. Other examples SAP, Salesforce .
c) Platform as a Service (PaaS): It provides a platform allowing end user to develop, run, and manage applications without the complexity of building and maintaining the infrastructure.
Google App Engine, CloudFoundry, Heroku, AWS (Beanstalk) are some examples of PaaS.
Below fig 1.0 while give you more idea on it.
d) Container as a Service (CaaS): Is a form of container-based virtualization in which container engines, orchestration and the underlying compute resources are delivered to users as a service from a cloud provider.
Google Container Engine(GKE), AWS (ECS), Azure (ACS) and Pivotal (PKS) are some examples of CaaS.
e) Function as a Service (FaaS): It provides a platform allowing customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure.
AWS (Lamda), Google Cloud Function are some examples of Faas
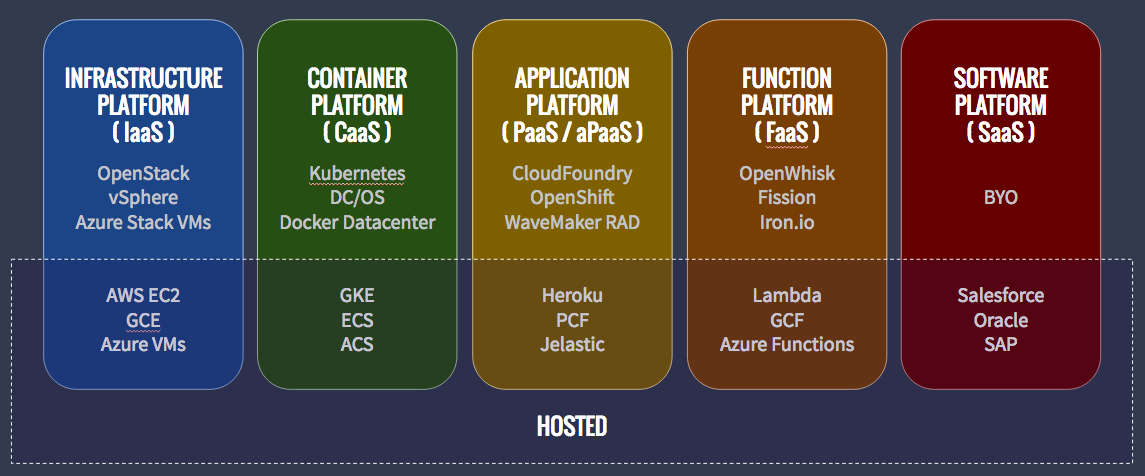
Hope this gives you clear idea on what are Cloud Computing Services provided in market!!!!!!


.jpg)




