Data Engineering
In simple words, Data Engineering is the heart of designing, building for collecting, storing, processing, and analyzing large amount of data at scale.
To put it straight, in data engineering we develop and maintain large scale data processing systems to prepare structured and unstructured data to perform analytical modeling and make data driven decisions.
The aim of data engineering is to make quality data available for analysis and efficient data-driven decision making.
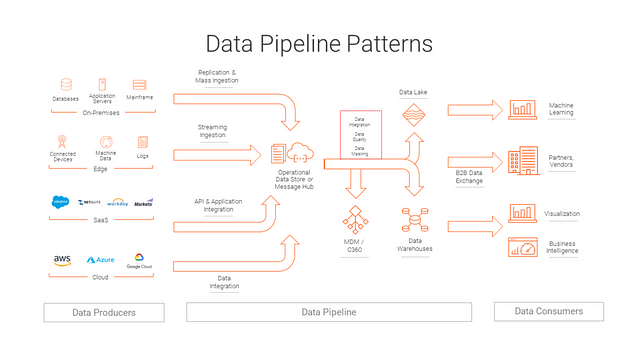
Most importantly, the Data Engineering ecosystem consists of 4 things —
Data — different data types, formats, and sources of data.
Data stores and repositories — Relational and non-relational databases, data warehouses, data marts, data lakes, and big data stores that store and process the data
Data Pipelines — Collect/Gather data from multiple sources, clean, process and transform it into data which can used for analysis,
Analytics and Data driven Decision Making — Make the well processed data available for further business analytics, visualization and data driven decision making.
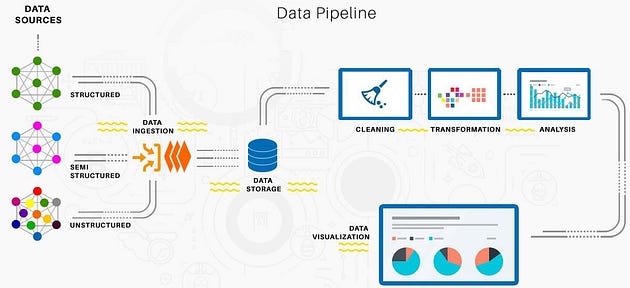
Why Data Engineering?
Data Engineering lifecycle consists of building/architecting data platforms, designing and implementing data stores and repositories, data lakes and gathering, importing, cleaning, pre-processing, querying, analyzing data, performance monitoring, evaluation, optimization and fine tuning the processes and systems.
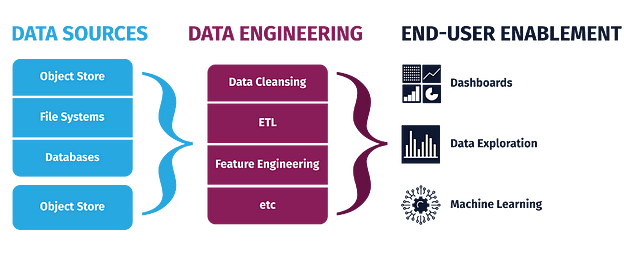
It gives a great edge —
1. To work and process with heterogeneous data formats and in the end get quality data that can be used in production.
2. To be able to work with large amount of data at scale and extract optimal value.
3. To automate the data pipelines and streams.
4. Use meta data efficiently.
5. To be able to derive amazing insights from the real time data ( quality data).
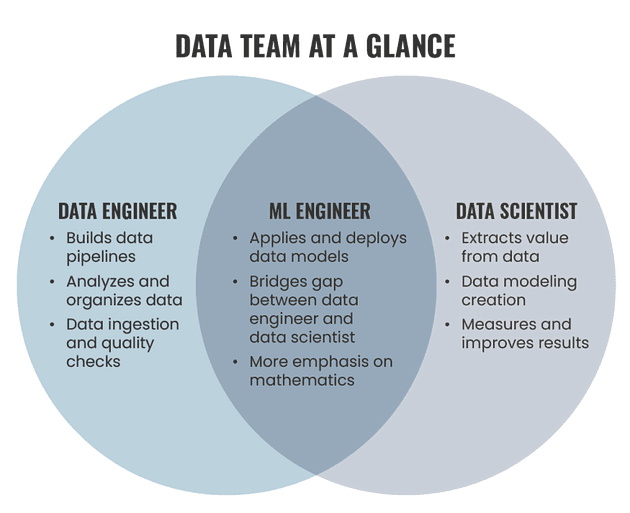
How Data Engineers are different from ML Engineers and Data Scientists?
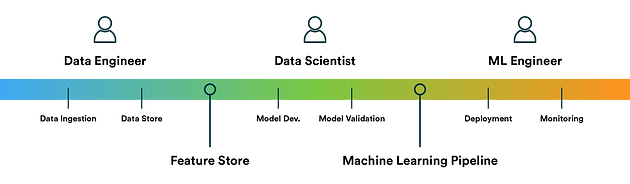
Data Engineers — To put it straight, data engineer is responsible for making quality data available from various resources, maintain databases, build data pipelines, query data, data preprocessing, Feature Engineering, Apache hadoop and spark, Develop data workflows using Airflow etc
Data Scientists and ML Engineers — On the other hand, ML Engineers and Data Scientists are responsible for building ML algorithms, building data and ML models and deploy them, have statistical and mathematical knowledge and measure, optimize and improve results.
Purpose, Scope and Responsibilities
Data Engineers are responsible for building the most efficient data infrastructure in order to process large amount of data coming from various sources.




No comments:
Post a Comment