Big Data File Format- Row-wise vs Columnar
This is found to be the most interesting and important topics when it comes to the data engineering or Big DataThere are basically 2 broad categories of file formats:-
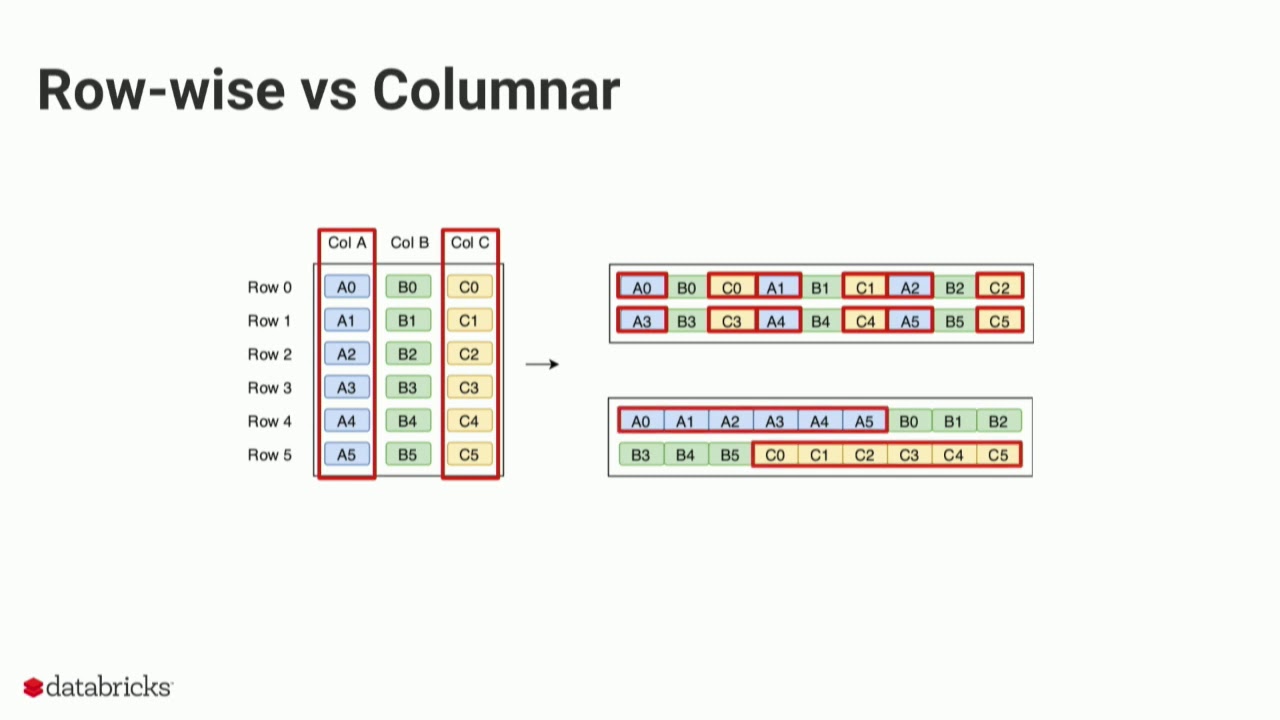
1. Row oriented File Formats:-
a. In row based file formats, the data is written in row-by-row fashion.
For example:-
Input Data:-
1 Sathish 1000
2 Ratheesh 2000
3 Sanjeev 3000
This data will be stored in the below following manner:-
| 1,Suresh,1000 | 2,Ramesh,2000 | 3,Rakesh,3000 |
b. This makes writing easy, as we can directly append the row at the end.
c. However, reading a subset of column is comparatively difficult or costly in terms of time as it needs to scan the entire row.
2. Column oriented File Formats:-
a. In column based file formats, the data is written in column-by-column fashion.
The same above input data is stored in below following manner:-
| 1,2,3 | Sathish,Ratheesh,Sanjeev | 1000,2000,3000 |
b. This makes reading easy as we can easily read the subset of column skipping the non-required columns.
c. However, writing is costly as we can't directly append the row at the end.
There are 3 types of Specialized File formats in Hive:-
1. Avro:-
a. It is a row-based file format, which means writes are faster but reads are slower.
b. The schema for Avro File Format is stored in JSON form which is embedded as a part of the data itself. This makes avro quite matured in terms of schema evolution.
c. However, the actual data is stored in compressed binary format which is efficient in terms of storage.
2. ORC:-
a. It is a column-based file format, which means reads are faster and writes are slower.
b. ORC provides best compression as compared to other file formats and supports schema evolution, metadata is stored in protocol buffers which allow addition and deletion of columns.
c. It also provides Predicate Pushdown, which means let us assume we have below the query:-
SELECT * FROM EMPLOYEE WHERE EMPLOYEE_ID=10001
Here, whatever present in where clause is known as predicate and it is considered first while the search operation by filtering out records thereby, providing quicker read operation.
3. Parquet:-
a. It is a column-based file format, which means writes are faster but reads are slower.
b. It stores metadata at the end of file so it is also considered quite matured (but not good as avro) in terms of schema evolution.
c. Addition and deletion of the columns in metadata can be done at end only.



No comments:
Post a Comment