Hive Interview Questions
Hive Architecture
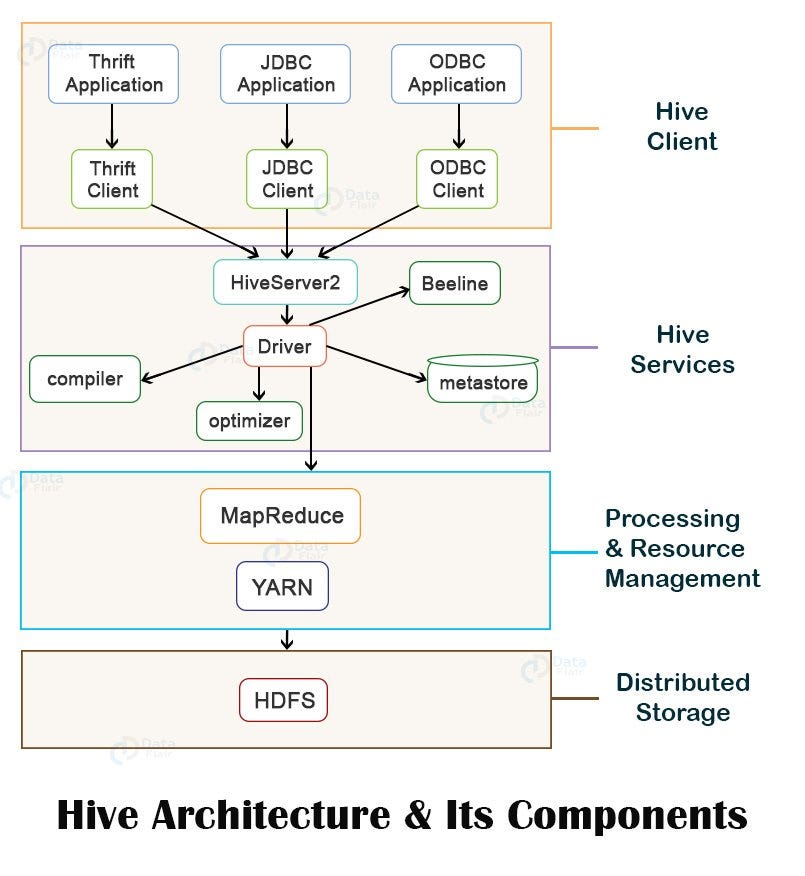
1. What are the components used in Hive Query Processor?
Following are the components of a Hive Query Processor:
- Parse and Semantic Analysis (ql/parse)
- Metadata Layer (ql/metadata)
- Type Interfaces (ql/typeinfo)
- Sessions (ql/session)
- Map/Reduce Execution Engine (ql/exec)
- Plan Components (ql/plan)
- Hive Function Framework (ql/udf)
- Tools (ql/tools)
- Optimizer (ql/optimizer)
2. What are Buckets in Hive?
Buckets in Hive are used in segregating Hive table data into multiple files or directories. They are used for efficient querying.
3. What is the maximum size of a string data type supported by Hive? Explain how Hive supports binary formats.
The maximum size of a string data type supported by Hive is 2 GB. Hive supports the text file format by default, and it also supports the binary format sequence files, ORC files, Avro data files, and Parquet files.
- Sequence file: It is a splittable, compressible, and row-oriented file with a general binary format.
- ORC file: Optimized row columnar (ORC) format file is a record-columnar and column-oriented storage file. It divides the table in row split. Each split stores the value of the first row in the first column and follows subsequently.
- Avro data file: It is the same as a sequence file that is splittable, compressible, and row-oriented but without the support of schema evolution and multilingual binding.
- Parquet file: In Parquet format, along with storing rows of data adjacent to one another, we can also store column values adjacent to each other such that both horizontally and vertically datasets are partitioned.
4. What is the precedence order of Hive configuration?
We are using a precedence hierarchy for setting properties:
- The SET command in Hive
- The command-line –hiveconf option
- Hive-site.XML
- Hive-default.xml
- Hadoop-site.xml
- Hadoop-default.xml
5. If you run a select * query in Hive, why doesn’t it run MapReduce?
The hive.fetch.task.conversion property of Hive lowers the latency of MapReduce overhead, and in effect when executing queries such as SELECT, FILTER, LIMIT, etc. it skips the MapReduce function.
6. What is the available mechanism for connecting applications when we run Hive as a server?
- Thrift Client: Using Thrift, we can call Hive commands from various programming languages, such as C++, PHP, Java, Python, and Ruby.
- JDBC Driver: JDBC Driver enables accessing data with JDBC support, by translating calls from an application into SQL and passing the SQL queries to the Hive engine.
- ODBC Driver: It implements the ODBC API standard for the Hive DBMS, enabling ODBC-compliant applications to interact seamlessly with Hive.
7. Mention various date types supported by Hive.
The timestamp data type stores date in the java.sql.timestamp format.
Three collection data types in Hive are:
- Arrays
- Maps
- Structs
8. Can we run UNIX shell commands from Hive? Can Hive queries be executed from script files? If yes, how? Give an example.
Yes, we can run UNIX shell commands from Hive using an ‘!‘ mark before the command. For example, !pwd at Hive prompt will display the current directory.
We can execute Hive queries from the script files using the source command.
Example:
Hive> source /path/to/file/file_with_query.hql9. Where does the data of a Hive table gets stored?
Ans. In an HDFS directory — /user/hive/warehouse, the Hive table is stored, by default only. Moreover, by specifying the desired directory in hive.metastore.warehouse.dir configuration parameter present in the hive-site.xml, one can change it.
10. What is a metastore in Hive?
Ans. Basically, to store the metadata information in the Hive we use Metastore. Though, it is possible by using RDBMS and an open source ORM (Object Relational Model) layer called Data Nucleus. That converts the object representation into the relational schema and vice versa.



Thanks for providing this information
ReplyDeleteBest Mulesoft Online Training in Hyderabad
Mulesoft Online Training in India