Spark Basic Architecture and Terminology
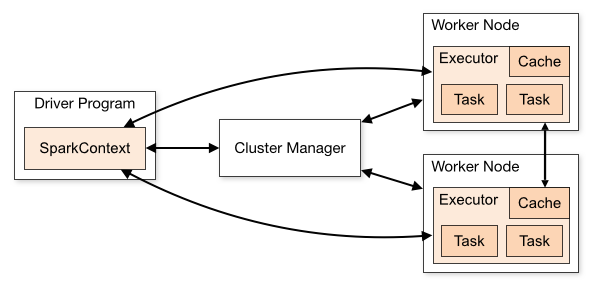
A Spark Application consists of a Driver Program and a group of Executors on the cluster. The Driver is a process that executes the main program of your Spark application and creates the SparkContext that coordinates the execution of jobs (more on this later). The executors are processes running on the worker nodes of the cluster which are responsible for executing the tasks the driver process has assigned to them.
The cluster manager (such as Mesos or YARN) is responsible for the allocation of physical resources to Spark Applications.
Entry Points
Every Spark Application needs an entry point that allows it to communicate with data sources and perform certain operations such as reading and writing data. In Spark 1.x, three entry points were introduced: SparkContext, SQLContext and HiveContext. Since Spark 2.x, a new entry point called SparkSession has been introduced that essentially combined all functionalities available in the three aforementioned contexts. Note that all contexts are still available even in newest Spark releases, mostly for backward compatibility purposes.
In the next sections I am going to discuss the purpose of the above entry points and how each differentiates from others.
SparkContext, SQLContext and HiveContext
As mentioned before, the earliest releases of Spark made available these three entry points each of which has a different purpose.
SparkContext
The SparkContext is used by the Driver Process of the Spark Application in order to establish a communication with the cluster and the resource managers in order to coordinate and execute jobs. SparkContext also enables the access to the other two contexts, namely SQLContext and HiveContext (more on these entry points later on).
In order to create a SparkContext, you will first need to create a Spark Configuration (SparkConf) as shown below:
// Scalaimport org.apache.spark.{SparkContext, SparkConf}val sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")
val sc = new SparkContext(sparkConf)
# PySparkfrom pyspark import SparkContext, SparkConfconf = SparkConf() \
.setAppName('app') \
.setMaster(master)
sc = SparkContext(conf=conf)
Note that if you are using the spark-shell, SparkContext is already available through the variable called sc.
SQLContext
SQLContext is the entry point to SparkSQL which is a Spark module for structured data processing. Once SQLContext is initialised, the user can then use it in order to perform various “sql-like” operations over Datasets and Dataframes.
In order to create a SQLContext, you first need to instantiate a SparkContext as shown below:
// Scalaimport org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.sql.SQLContextval sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
# PySparkfrom pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContextconf = SparkConf() \
.setAppName('app') \
.setMaster(master)sc = SparkContext(conf=conf)
sql_context = SQLContext(sc)
HiveContext
If your Spark Application needs to communicate with Hive and you are using Spark < 2.0 then you will probably need a HiveContext if . For Spark 1.5+, HiveContext also offers support for window functions.
// Scalaimport org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContextval sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)hiveContext.sql("select * from tableName limit 0")
# PySparkfrom pyspark import SparkContext, HiveContextconf = SparkConf() \
.setAppName('app') \
.setMaster(master)sc = SparkContext(conf)
hive_context = HiveContext(sc)
hive_context.sql("select * from tableName limit 0")
Since Spark 2.x+, tow additions made HiveContext redundant:
a) SparkSession was introduced that also offers Hive support
b) Native window functions were released and essentially replaced the Hive UDAFs with native Spark SQL UDAFs
SparkSession
Spark 2.0 introduced a new entry point called SparkSession that essentially replaced both SQLContext and HiveContext. Additionally, it gives to developers immediate access to SparkContext. In order to create a SparkSession with Hive support, all you have to do is
// Scalaimport org.apache.spark.sql.SparkSessionval sparkSession = SparkSession \
.builder() \
.appName("myApp") \
.enableHiveSupport() \
.getOrCreate()// Two ways you can access spark context from spark session
val spark_context = sparkSession._sc
val spark_context = sparkSession.sparkContext
# PySparkfrom pyspark.sql import SparkSessionspark_session = SparkSession \
.builder \
.enableHiveSupport() \
.getOrCreate()# Two ways you can access spark context from spark session
spark_context = spark_session._sc
spark_context = spark_session.sparkContext
Conclusion
In this article we went through the older entry points (SparkContext, SQLContext and HiveContext) that were made available in early releases of Spark.
We have also seen how the newest entry point namely SparkSession has made the instantiation of the other three contexts redundant. If you are using Spark 2.x+, then you shouldn’t really worry about HiveContext, SparkContext and SQLContext. All you have to do is to create a SparkSession that offers support to Hive and sql-like operations. Additionally, in case you need to access SparkContext for any reason, you can still do it through SparkSession as we have seen in the examples of the previous session. Another important thing to note is that Spark 2.x comes with native window functions that initially were introduced in HiveContext.
PS: If you are not using Spark 2.x yet, I strongly encourage you start doing so.



No comments:
Post a Comment