Big Data And Hadoop interview questions
1. What are the differences between regular FileSystem and HDFS?
- Regular FileSystem: In regular FileSystem, data is maintained in a single system. If the machine crashes, data recovery is challenging due to low fault tolerance. Seek time is more and hence it takes more time to process the data.
- HDFS: Data is distributed and maintained on multiple systems. If a DataNode crashes, data can still be recovered from other nodes in the cluster. Time taken to read data is comparatively more, as there is local data read to the disc and coordination of data from multiple systems.
2. Why is HDFS fault-tolerant?
HDFS is fault-tolerant because it replicates data on different DataNodes. By default, a block of data is replicated on three DataNodes. The data blocks are stored in different DataNodes. If one node crashes, the data can still be retrieved from other DataNodes.
3. What are the two types of metadata that a NameNode server holds?
The two types of metadata that a NameNode server holds are:
- Metadata in Disk — This contains the edit log and the FSImage
- Metadata in RAM — This contains the information about DataNodes
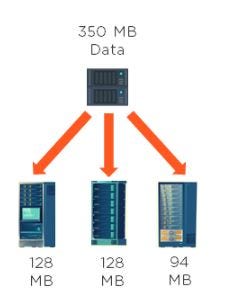
4. If you have an input file of 350 MB, how many input splits would HDFS create and what would be the size of each input split?
By default, each block in HDFS is divided into 128 MB. The size of all the blocks, except the last block, will be 128 MB. For an input file of 350 MB, there are three input splits in total. The size of each split is 128 MB, 128MB, and 94 MB.
5. How does rack awareness work in HDFS?
HDFS Rack Awareness refers to the knowledge of different DataNodes and how it is distributed across the racks of a Hadoop Cluster.
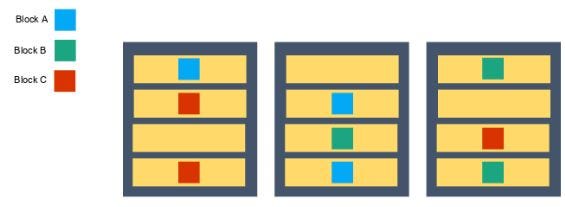
By default, each block of data is replicated three times on various DataNodes present on different racks. Two identical blocks cannot be placed on the same DataNode. When a cluster is “rack-aware,” all the replicas of a block cannot be placed on the same rack. If a DataNode crashes, you can retrieve the data block from different DataNodes.
6. How can you restart NameNode and all the daemons in Hadoop?
The following commands will help you restart NameNode and all the daemons:
You can stop the NameNode with ./sbin /Hadoop-daemon.sh stop NameNode command and then start the NameNode using ./sbin/Hadoop-daemon.sh start NameNode command.
You can stop all the daemons with ./sbin /stop-all.sh command and then start the daemons using the ./sbin/start-all.sh command.
7. Which command will help you find the status of blocks and FileSystem health?
To check the status of the blocks, use the command:
hdfs fsck <path> -files -blocks
To check the health status of FileSystem, use the command:
hdfs fsck / -files –blocks –locations > dfs-fsck.log
8. What would happen if you store too many small files in a cluster on HDFS?
Storing several small files on HDFS generates a lot of metadata files. To store these metadata in the RAM is a challenge as each file, block, or directory takes 150 bytes for metadata. Thus, the cumulative size of all the metadata will be too large.
9. How do you copy data from the local system onto HDFS?
The following command will copy data from the local file system onto HDFS:
hadoop fs –copyFromLocal [source] [destination]
Example: hadoop fs –copyFromLocal /tmp/data.csv /user/test/data.csv
In the above syntax, the source is the local path and destination is the HDFS path. Copy from the local system using a -f option (flag option), which allows you to write the same file or a new file to HDFS.
10. Is there any way to change the replication of files on HDFS after they are already written to HDFS?
Yes, the following are ways to change the replication of files on HDFS:
We can change the dfs.replication value to a particular number in the $HADOOP_HOME/conf/hadoop-site.xml file, which will start replicating to the factor of that number for any new content that comes in.
If you want to change the replication factor for a particular file or directory, use:
$HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /path of the file
Example: $HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /user/temp/test.csv



No comments:
Post a Comment